目录
2023-2-9
MQ message queue
rocketMQ、RabbitMQ、Kafka、ActiveMQ
技术挑战不是特别高,用 RabbitMQ 是不错的选择,
电商、金融等对事务性要求很高的,可以考虑RocketMQ,
如果是大数据领域的实时计算、日志采集等场景可以考虑 Kafka。
mq如何测试:
对于生产者:
- 生成的数据格式是否跟定义的一致
- 数据是否有成功推送到队列中对应topic
- 推送失败、重复推送如何处理
- 不同顺序推送,关注队列优先级
- 推送耗时,队列容量达到上限后,如何处理
对于消费者:
- 消费的消息是否来自对应订阅的topic,内容是否一致
- 优先级是否一致
- 消费者宕机,消息挤压,积压后超时如何处理
- 如何处理重复消息,幂等问题
- 消息处理失败,如加密的消息体消费者解密失败如何处理
- 消费消息耗时
对于队列本身:
- 宕机恢复后,消息是否丢失,不同的消息格式是否能正常识别及转发
怎么保障 mq
消息的有序性、幂等性、可靠性
- 有序性:队列有序,消息有序;队列无序,消息有序;队列有序,消息无序;队列无序,消息无序。
- 幂等性:消息的幂等性,可以通过消息的唯一标识(消息ID)来实现。
- 可靠性:消息的可靠性,可以通过消息的持久化来实现。
Redis remote dictionary server
远程字典服务是一个将数据存储在内存中速度非常快的非关系数据库
如何测试 Redis 缓存?
增:增加缓存,校验功能和数据是否正确符合业务DB和redis一致,过期时间和设计一致
删:删除缓存,校验功能和数据是否正确,再次请求缓存是否正确写入,DB和redis是否一致
改:更新缓存,校验功能和数据是否正确,DB和redis是否一致,过期时间和设计一致
查:
- 校验数据在缓存和DB都存在时,系统是否正常
- 校验数据在DB存在但缓存不存在,系统是否正常
- 校验数据在缓存和DB都不存在,系统是否正常
- 验证DB返回数据异常,系统有没有去查缓存
过期时间: 设置redis过期时间,校验缓存是否正常过期,再次写入时间是否被刷新
异常场景:
缓存超时: 缓存查询超时后,未能返回指定数据,系统反应是否符合预期
缓存穿透:查询一个DB和缓存中不存在的数据,验证数据是否返回空
缓存雪崩:设置大量key过期时间同时失效,系统指标是否正常,功能是否正常
缓存击穿:将一个key(缓存中存在,DB中也存在)删除,大并发访问刚刚删除的key,校验功能指标
缓存预热:在预热期间,系统接口是否正常
缓存上限:确认淘汰机制,然后将缓存数据增加到maxmemory,再请求查询数据返回正确,淘汰机制正确
缓存停服:关闭redis后,系统功能和性能情况,重启后数据未丢失损坏和DB一致
缓存并发:
- 并发请求缓存中有的数据,验证返回数据符合预期,性能ok
- 并发请求缓存中没有DB有的数据
- 并发请求缓存中没有DB中也没有的数据,验证返回数据为空
缓存性能测试:一般用 redis-benchmark
- 对比单机和集群redis的tps
生成环境的监控:缓存命中率、cpu、内存、是否有大key
redis内存满了,会发生什么?
当redis内存到达某个阈值会触发内存淘汰机制。
八大内存淘汰机制:noeviction默认策略,内存慢了不淘汰数据不提供服务
进行数据淘汰的策略
针对「进行数据淘汰」这一类策略,又可以细分为「在设置了过期时间的数据中进行淘汰」和「在所有数据范围内进行淘汰」这两类策略。 在设置了过期时间的数据中进行淘汰:
- volatile-random:随机淘汰设置了过期时间的任意键值;
- volatile-ttl:优先淘汰更早过期的键值。
- volatile-lru(Redis3.0 之前,默认的内存淘汰策略):淘汰所有设置了过期时间的键值中,最久未使用的键值;
- volatile-lfu(Redis 4.0 后新增的内存淘汰策略):淘汰所有设置了过期时间的键值中,最少使用的键值;
在所有数据范围内进行淘汰:
- allkeys-random:随机淘汰任意键值;
- allkeys-lru:淘汰整个键值中最久未使用的键值;
- allkeys-lfu(Redis 4.0 后新增的内存淘汰策略):淘汰整个键值中最少使用的键值。
redis用的是淘汰缓存还是更新缓存?
淘汰缓存:
- 更新DB后,将缓存中记录删除
- 查询数据时,无法从缓存获取数据,遂从DB获取后写入缓存
- 第二次及之后查询该数据,直接从缓存读取
更新缓存:
- 有缓存的调用者更新DB同时更新缓存
- 查询该数据时,从缓存读取最新数据
区别:淘汰缓存更新数据会有一次缓存穿透,更新缓存无此情况,但是更新缓存每次都同时更新缓存比较影响性能,大部分情况下修改数据成本高于一次缓存穿透,选用淘汰缓存更合理
redis用途和场景
remote dictionary server
- 解决应用服务器的cpu和内存压力
- 减少IO的读操作,减轻IO压力
场景:
充当缓存系统,为热点数据(读多写少)
计数器、限流器:限制一个手机发多少条短信、一个接口一分钟限制多少请求、一天内限制请求次数
消息队列系统、排行榜、社交网络、实时性高的系统(共享session、分布式锁)
限时业务:限时优惠活动、手机验证码
缓存、数据共享分布式、分布式锁、全局 ID、计数器、限流、购物车、消息队列、抽奖、点赞、签到、打卡等场景。
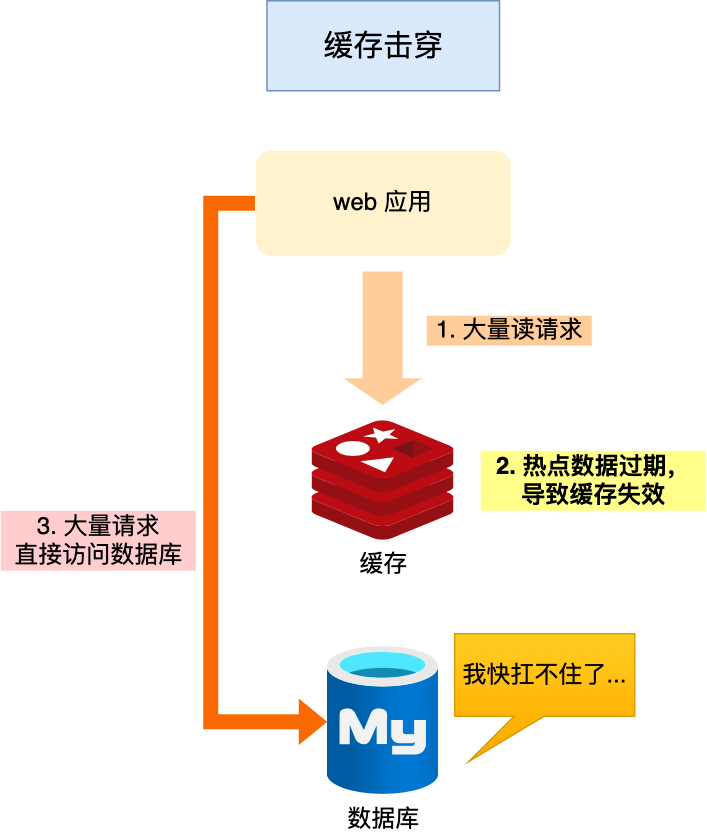
redis击穿
当redis获取某一个key时,由于key失效或不存在,向DB请求称为redis击穿

引发击穿原因:第一次访问、恶意访问不存在的key、key过期
规避方案:
服务启动时,提前写入:
规范key命名,通过中间件拦截
对高频key,设置ttl永不过期,或者过期时间设置成加上随即数
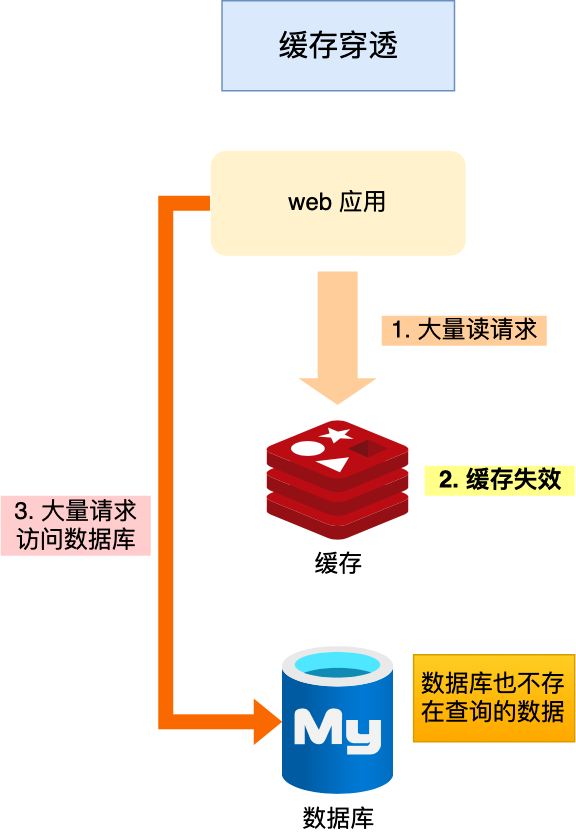
redis穿透
业务查询的数据既不在redis也不在DB,成为穿透
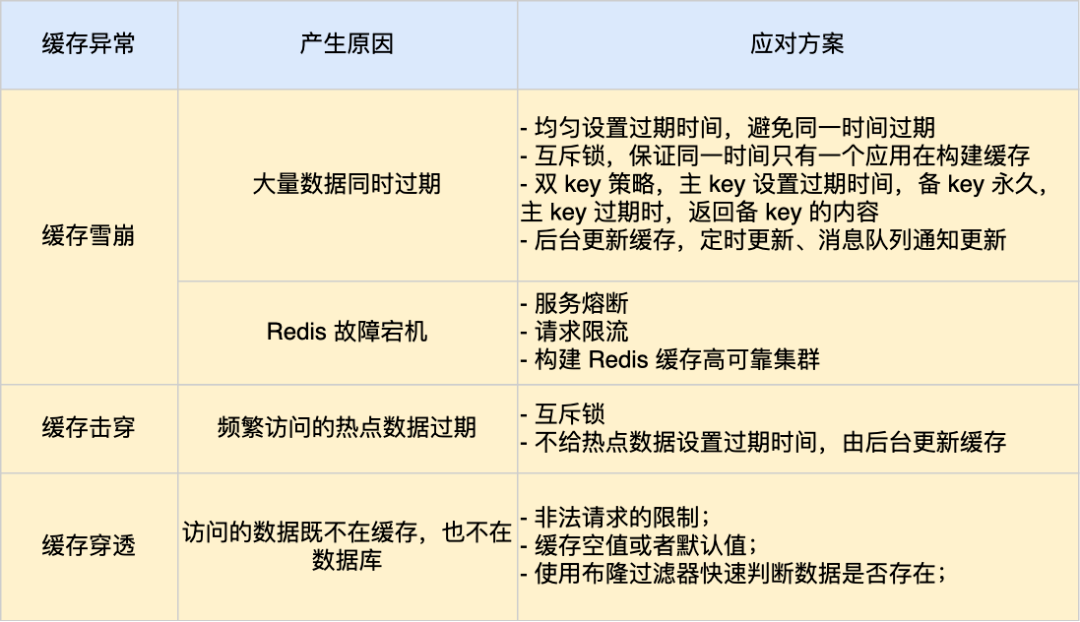
 ## redis雪崩
## redis雪崩
redis缓存层由于大量数据同时过期、redis故障宕机,所有请求都涌向储存层,短时高并发请求可能导致储存层宕机,
引起一系列连锁反应,造成整个系统崩溃
称之为redis雪崩,redis击穿是redis雪崩的一个子集
规避方案:对于大量数据同时过期:均匀的设置过期时间、互斥锁、双key策略、后台更新缓存
对于redis故障宕机:服务熔断、请求限流机制,使用redis高可用集群
2023-2-10
mqtt的mosquito有哪些测试点
- 连接测试:测试Mosquitto服务端是否可以连接上客户端,以及客户端是否可以正确发布和订阅消息。
- 订阅测试:测试客户端是否能够正确订阅消息,以及客户端是否可以接收到相应的消息。
- 发布测试:测试Mosquitto服务端是否能够接收和发布客户端发出的消息请求。
- 流量测试:测试Mosquitto服务端在访问高峰期时能够承受多少流量。
- 性能测试:测试Mosquitto服务端在多客户端访问情况下可以提供多少消息维护和传输性能。
- 错误处理测试:测试Mosquitto服务端如何处理各种错误和异常情况。