目录
2023-2-2
https://3.jetbra.in/ 激活pycharm网址
2022-10-24
安装ycharm问题:
从2019版本升级2022版本超过3G,增量更新导致17G的盘空余空间不够,卸载重装解决,但是丢失了许可证,现在的pycharm试用需要登陆账号,还不能使用临时邮箱注册:(
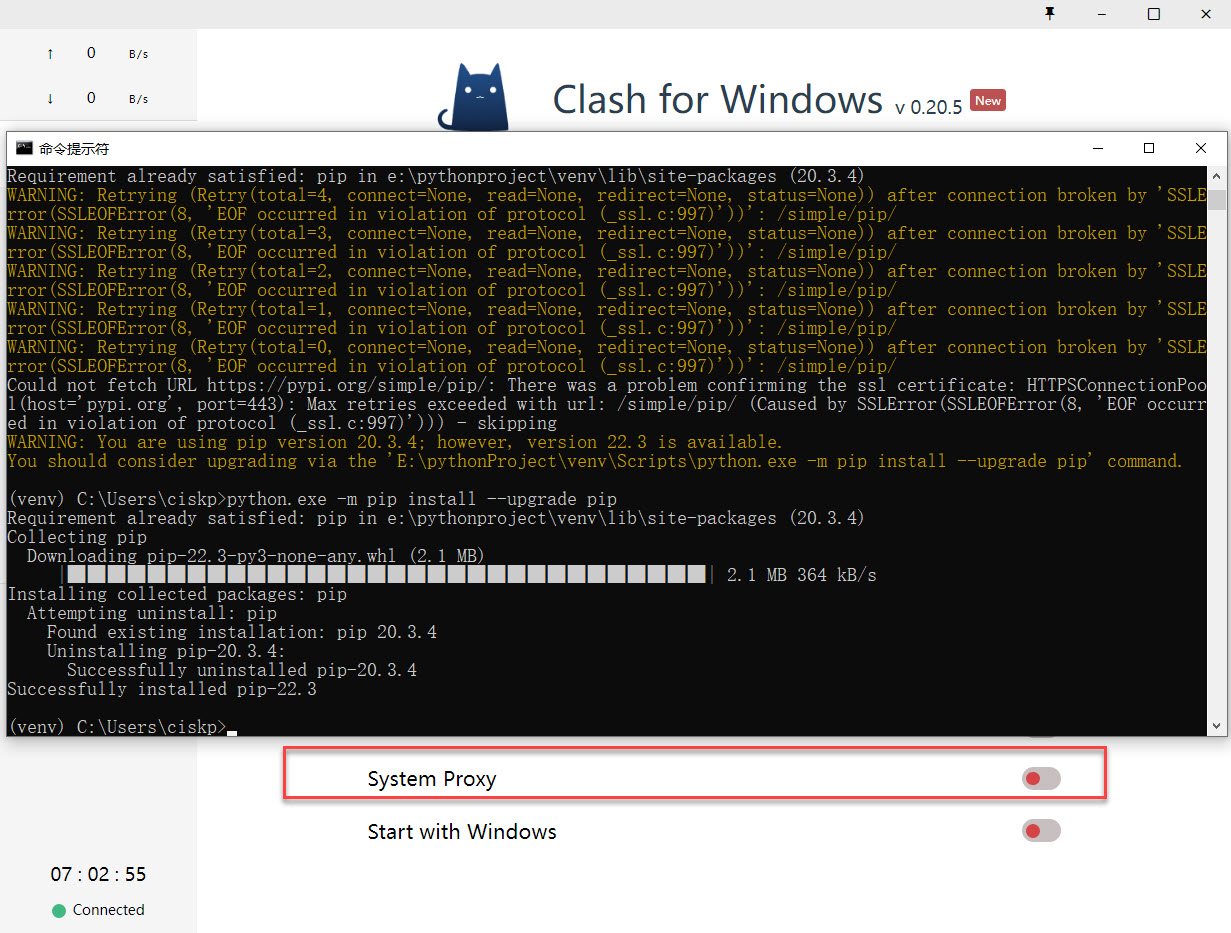
安装pytest问题(用pip install pytest报错No matching distribution found for pytest Could not find a version that sa
ssl解析问题因为这个包的镜像地址解析出问题,可能因为墙的原因):
pip install pytest -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
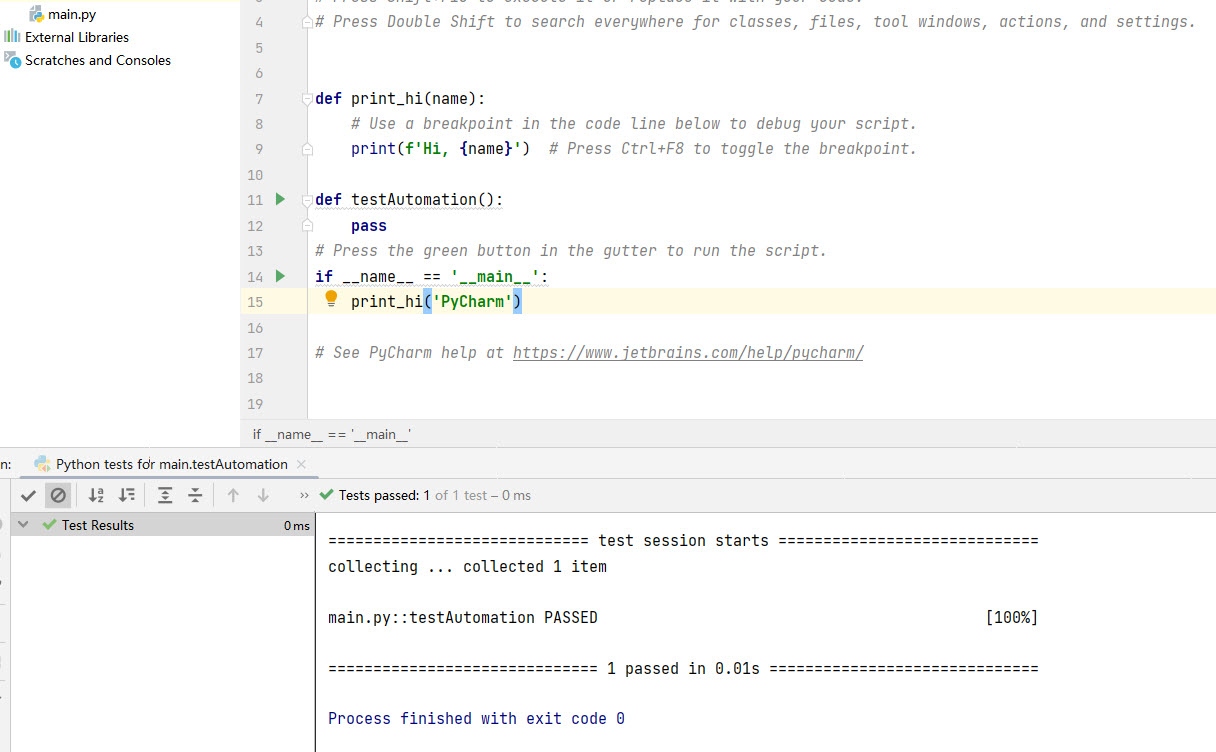
 写下第一个pytest函数:
写下第一个pytest函数:
pythondef testAutomation():
pass
注意def左边出现了播放按钮,这代表pytest安装好了,而且下面有运行结果。
2022-10-25
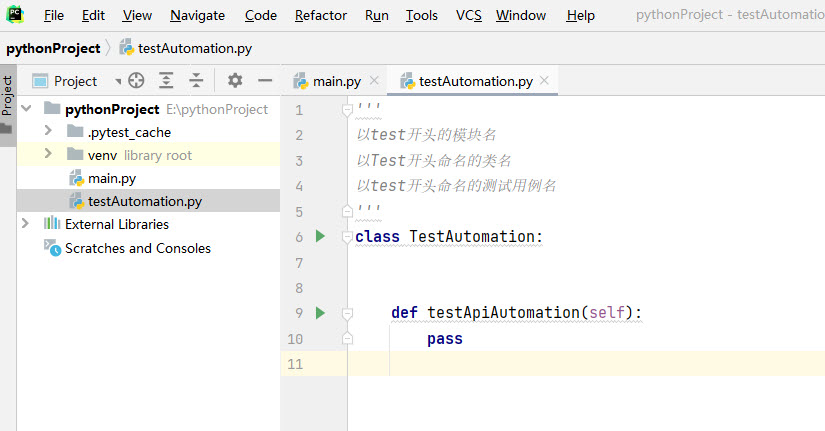
Pytest的测试用例命名规则
1.模块名(xx.py)必须以test_ 开头,或者 _test结尾
2.类名(class)必须以test开头
3.测试用例(def testAuto)必须以test_开头
pythondef get(url, params=None, **kwargs):
def post(url, data=None, json=None, **kwargs):
def put(url, data=None, **kwargs):
def delete(url, **kwargs):
#上面四个方法会调用下面的方法
def requests.request(method, url, **kwargs)
#上面的方法会调用下面的request方法
def session.request(self,
method,#请求方式
url,#请求路径
params=None,#get的请求传参
data=None,#get或者put的传参
headers=None,#请求头
cookies=None,#请求头里面的cookie信息
files=None,#文件上传
auth=None,#鉴权
timeout=None,设置超时时间
allow_redirects=True,是否允许重定向
proxies=None,设置代理
hooks=None,设置钩子函数
stream=None,#文件下载
verify=None,ssl证书是否验证
cert=None,ca证书路径
json=None,json格式参数
)
def session():#获得的是会话对象
requests.request()session.requests()区别
前者的每个请求都是独立的,后者会自动关联所有请求的cookie信息
pythonrequests.response返回对象的常用方法:
res.text #获取返回的字符串
res.content #获取返回字节数据
res.json() #获取返回json数据,python中把json叫作字典,
这个.json是方法,其他的是repsonse的属性
res.status_code #获取返回状态码
res.reason #获取返回状态信息
res.cookies #获取返回响应cookie
res.encoding #获取返回响应编码
res.headers #获取返回响应头
res.request.xxx #获取返回请求的一些信息
*args **kwargs区别
*args(Non-keyword Variable Arguments)无关键字参数:当函数中以列表或元组形式传参时用它(a,b,c,d,e)→(a,b)→(7, g)
**kwargs(keyword Variable Arguments)有关键字参数: 当函数中以字典形式传参时用它
{
“a”:1, “b”:2, “c”:3, “d”:4, “e”:5
}→
{
“a”:1, “b”:2
}
安装requests库遇到问题:
Could not fetch URL https://pypi.org/simple/requests/: There was a problem confirming the ssl certificate
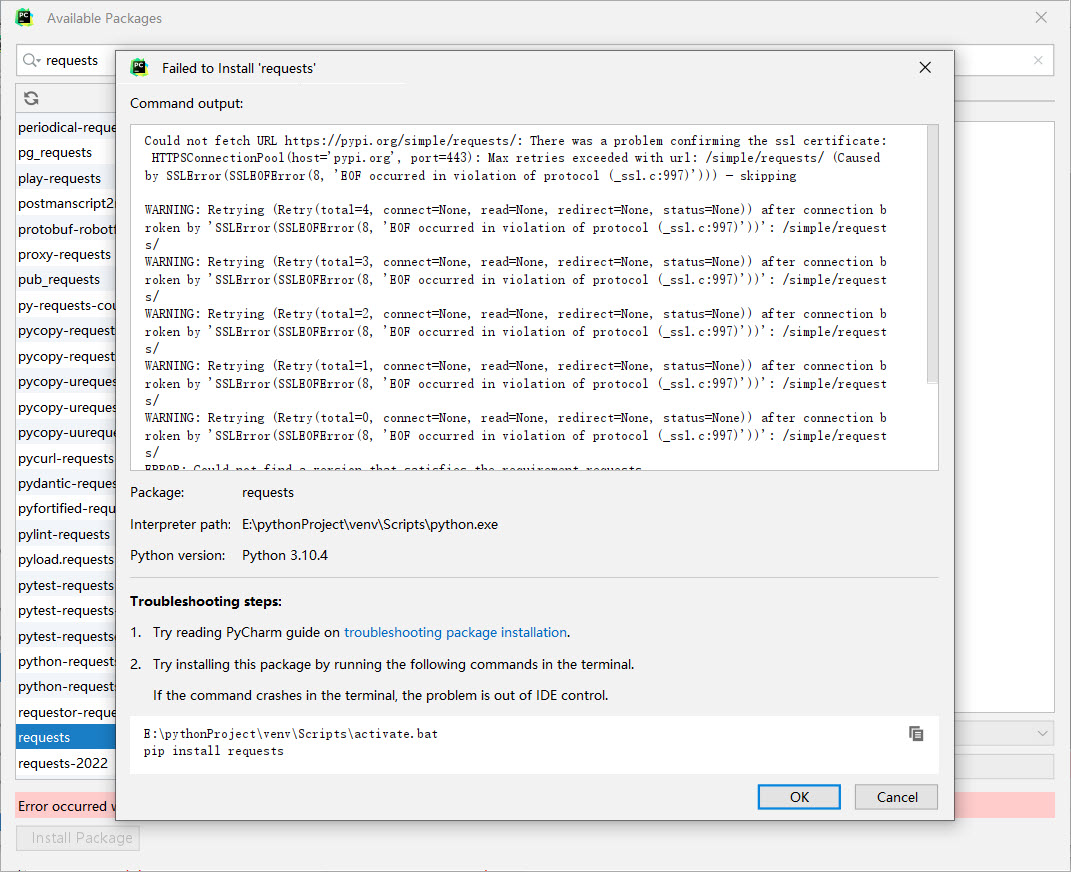 解决方法:把代理关闭,可能代理的出口IP被cdn防火墙拦截了,导致每次下载请求被拒绝
解决方法:把代理关闭,可能代理的出口IP被cdn防火墙拦截了,导致每次下载请求被拒绝
2022-11-26
Get请求通过params传参
Post请求通过data和json传参
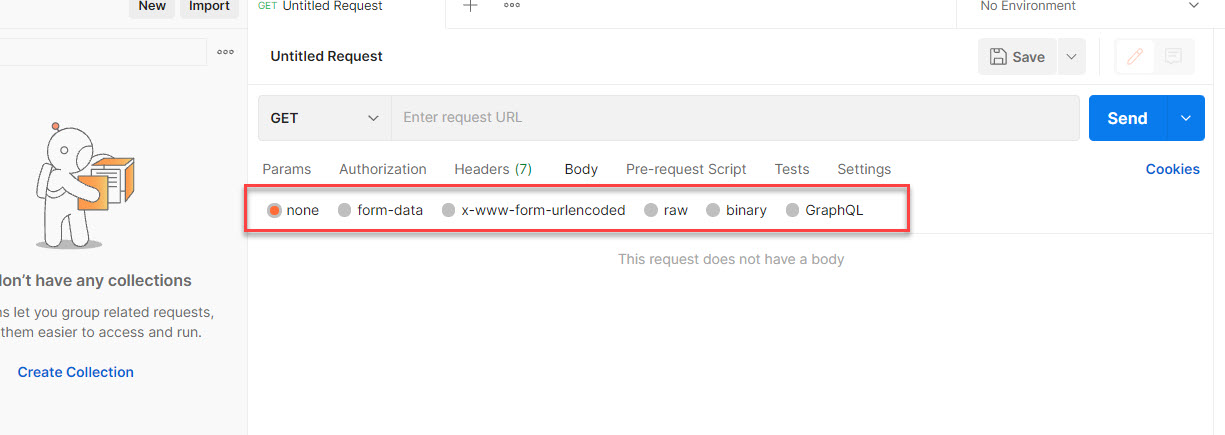
Form-data传参除了文件上传使用files参数接收,
其他类型对应python.requests中data, X-www-form-urlencoded对应data,
Raw中json使用json格式从传参其他的都用data, Binary使用data传参
2022-10-27
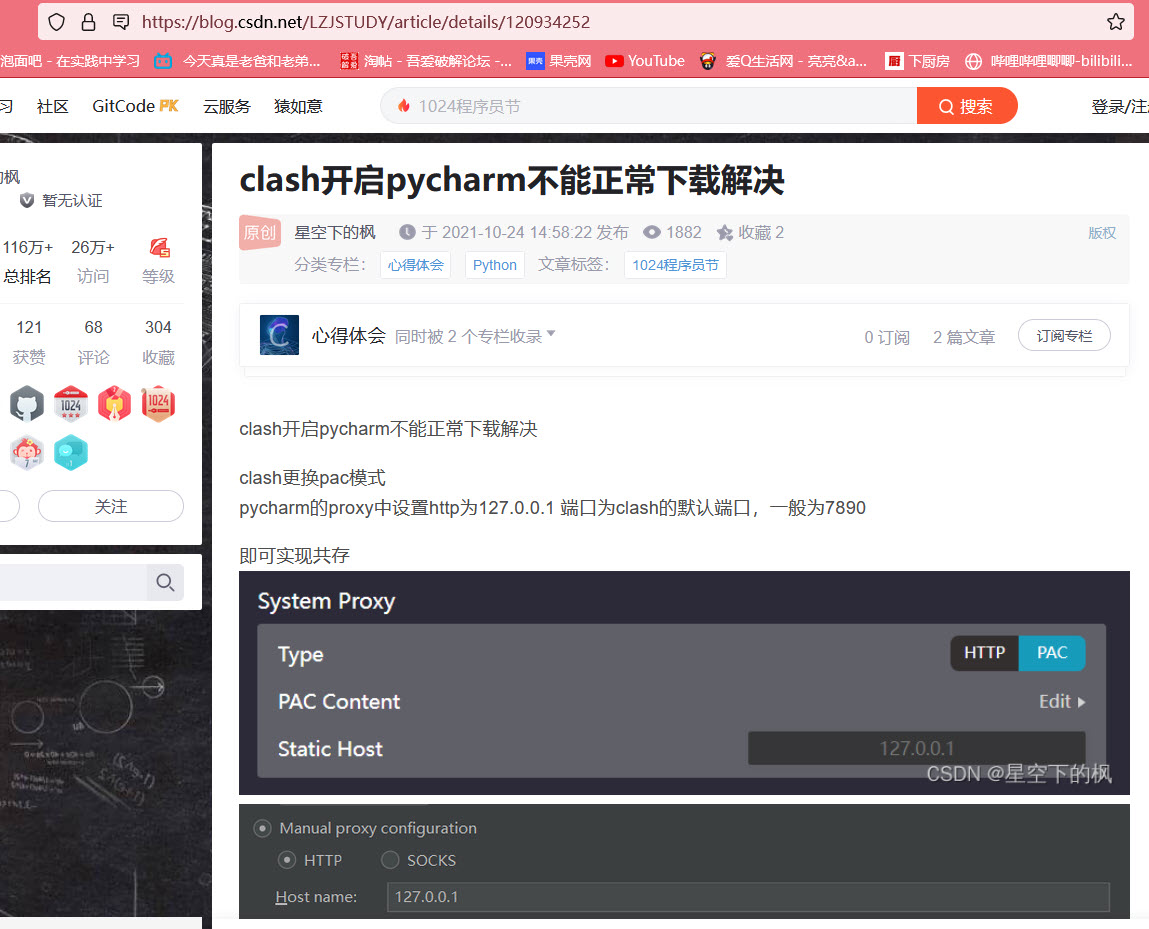
使用clash软件和pycharm产生的化学反应:
Certificate_Verify_Failed类似a证书验证失败的报错,具体表现在使用pip命令下载各种第三方包时候会报错ssl错误,起初以为ssl证书版本过低,更新版本后,还是报错,遂搜索clash与pycharm
https://blog.csdn.net/LZJSTUDY/article/details/120934252
切换为PAC后,正常使用requests请求网址,但是原理为何,后面再补充
Requests接口关联的三个层次:
1.通过类变量保存中间变量(弊端:模块之间有关联的情况下导入类后,类中的用例也被导入。导致用例重复执行)
2.单独的文件保存中间变量
3.极限封装成零代码保存中间变量
Requests接口关联的两种方法:
(1)re.search()正则匹配到一个值,通过下标类似索引取值,没有匹配到返回None
pythonre.search('"age":"(.*?)"', result.json).group(1)
re.findall()正则匹配多个值,返回list,通过下标取值,没匹配到返回None
(2)jsonpath.jsonpath()返回一个列表,通过下标取值。没匹配到返回None
python
2022-10-29
统一请求封装
1.去除重复的冗余的代码,2.实现统一的异常处理和日志监控
pythonimport requests
import jsonpath
class TestApi:
# token=""
# 使用全局变量接收函数的中间变量
def testRegister(self):
url='https://reqres.in/api/register'
data={
"email": "eve.holt@reqres.in",
"password": "pistol"
}
# TestApi.token = requests.post(url, json=data).json()["token"]
return requests.post(url, json=data).json()["token"]
# print(requests.post(url, json=data).json()["token"])
# return jsonpath.jsonpath(requests.post(url, json=data), "$.token")[0]
# print(jsonpath.jsonpath(requests.post(url, json=data).json(), "$.token")[0])
def testLogin(self):
url = 'https://reqres.in/api/login'
data = {
"email": "eve.holt@reqres.in",
"password": "cityslicka",
"token": TestApi.testRegister(self)
}
print(requests.post(url, json=data).request.body)
if __name__ == '__main__':
TestApi()
重构上述项目
pythonimport requests
from common.requestsUtils import RequestsUtils
class TestApi:
# token=""
# 使用全局变量接收函数的中间变量
def testRegister(self):
url='https://reqres.in/api/register'
data={
"email": "eve.holt@reqres.in",
"password": "pistol"
}
return RequestsUtils().sendRequest(method="post", url=url, json=data)["token"]
def testLogin(self):
url = 'https://reqres.in/api/login'
data = {
"email": "eve.holt@reqres.in",
"password": "cityslicka",
"token": TestApi.testRegister(self)
}
print(RequestsUtils().sendRequest(method="post", url=url, json=data))
if __name__ == '__main__':
TestApi()
pythonimport requests
class RequestsUtils:
session = requests.session()
#统一请求封装
def sendRequest(self,**kwargs):
response = RequestsUtils.session.request(**kwargs)
return response.json()
Pytest用例管理框架详细说明
该框架结合selenium、requests、appium实现web、api、app自动化
结合allure生成美观的报告集成CICD到流水线
框架常用插件如下:
pythonpytest 本身 pytest-html 生成html报告 pytest-xdist 多线程执行 pytest-ordering 控制用例的执行顺序 pytest-rerunfailures 失败的用例重跑 pytest-base-url 基础路径,用于切换不同的环境dev、qa、uat、prod allure-pytest 生成allure报告
pip install -r requirements.txt #一次性安装依赖
pytest用例管理框架执行的三种方式:
1.命令行
powershellpytest
2.主函数
pythonimport pytest
if __name__ == '__main__':
pytest.main()
3.通过放在项目的根目录下的配置文件pytest.ini编码格式ANSI(中文要用gbk模式)来改变以及执行用例
不论是命令行还是主函数,都会读取pytest.ini文件来执行
python[pytest]
#配置参数
addopts = -vs -m "smoke or user"
#-v输出详细信息 -s输出调试信息 如:pytest -vs
#多线程运行(前提得安装插件pytest-xdist)如:pytest -vs -n=2
#--reruns num 失败重跑(前提安装插件pytest-rerunfailures)例如:pytest -vs --reruns=2
# raise Exception 抛出异常
# try except 解决异常
#-x出现一个用例失败则停止测试,如:pytest -vs -x
#改变用例查找规则
#--maxfail 出现几个失败才终止,如pytest -vs --maxfail=2
#--html生成html的测试报告(前提得安装插件pytest-html)如:pytest -vs --html ./result.html
#-k 运行测试用例名称中包含某个字符串的测试用例如:pytest -vs -k "注册 or 登录"或者"注册 and 登录"
testpaths = ./testcase
#改变模块查找规则
python_files = test_*.py
#改变类的查找规则
python_classes = Test*
#改变函数的查找规则
python_functions = test_*
#标记,例如冒烟测试
markers =
smoke:冒烟用例
user:用户管理
2022-10-30
pytest框架的前后置固件、夹具
传统的:
python def setup(self):
print("每个用例函数之前的操作")
def teardown(self):
print("每个用例函数之后的操作")
def setup_class(self):
print("每个类之前的操作")
def teardown_class(self):
print("每个类之后的操作")
conftest.py fixture
强大的前后置fixture固件、夹具(pytest的夹具,本质就是一个函数加上fixture装饰器)
单独的conftest.py中封装该夹具在testcase目录下
如果conftest.py在根目录则所有py文件都可使用
如果conftest.py在testcase目录下,则这里的conftest.py只在对应文件夹下作用
装饰器:
python@pytest.fixture(scope=scope,params=params,autouse=autouse,ids=ids,name=name)
#scope(作用域):``"function"`` (default), ``"class"``, ``"module"``, ``"package"`` or ``"session"``,优先级:session>class>function
#autouse:True所有用例自动使用夹具,False不自动使用,手动调用装饰函数,调用方式在测试用例的参数里加入fixture的名称如:@pytest.mark.usefixtures("ConnectDB")
#params:参数化传输你想传输的东西使用列表:["mysql", "redis"]列表中可嵌套字典,作用是可将同一份用例以不同的参数执行多次,这里第一次执行mysql,第二次执行redis
#ids:参数化
#name:夹具别名,用了该参数,原来的名字不能使用失效了
python@pytest.mark.skip(reason='无理由跳过')
@pytest.mark.skipif(workage<10, reason='工作经验少于10年跳过')
python# fixture固件
import pytest
@pytest.fixture(scope="function", autouse=False)
def connMysql():
print("连接数据库")
yield
print("关闭数据库")
#yeild和return区别:yield后面可以接代码运行,return后面无法接代码
对文件yaml的读取写入清空
pythonimport yaml
import os
# 写入追加
def writeYaml(data):
with open(os.getcwd() + "\extract.yaml", mode="a+", encoding="utf-8") as f:
yaml.dump(data, stream=f, allow_unicode=True)
# 读取
def readYaml(key):
with open(os.getcwd() + "\extract.yaml", mode="r", encoding="utf-8") as f:
value = yaml.load(stream=f, Loader=yaml.FullLoader)
return value[key]
# 清空
def clearYaml():
with open(os.getcwd() + "\extract.yaml", mode="w", encoding="utf-8") as f:
f.truncate()
# 读取测试用例
def readTestcase(yamlpath):
with open(os.getcwd() + "/" + yamlpath, mode="r", encoding="utf-8") as f:
value = yaml.load(f, yaml.FullLoader)
return value
yaml详细使用方法
yaml是以重数据格式,扩展名可以是yaml,yml。支持#注释,通过缩进表示层级
用于做配置文件,用于编写自动化测试用例
数组组成:1.map对象(字典dict) 键:(空格)值
2.数组对象(列表list)用一组"-"开头
yamltoken: QpwL5tke4Pnpja7X4 #解析出来是字典dict{"token":"QpwL5tke4Pnpja7X4"}
- name1: C
- name2: J
#解析出来是一个列表list中间嵌套字典[{"name1":"C"}, {"name2":"J"}]
用yaml写用例格式:
yaml-
featrue: 模块
story: 接口
title: 用例标题
request:
method: 请求方式
url:请求路径
headers:请求头
params/data/json/files: 参数
validate:断言
#validate: null对应python中None
数据驱动@pytest.mark.parametrize
python@pytest.mark.parametrize("数据驱动的参数名", "数据驱动的值")
python@pytest.mark.parametrize('classinfo', ['take', 'down'])
def test_001(self, caseinfo):
print(caseinfo)
@pytest.mark.parametrize('arg1, arg2', [['action', 'take'],['do', 'down']])
def test_002(self, arg1, arg2):
print(str(arg1)+ ' ' +str(arg2))
yaml中无法调用python函数,需要写死后传给用例中重新赋值
2022-10-31
1.allure-pytest安装
powershellpip isntall allure-pytest
2.Allure报告,选择最新版的zip包下载,解压后将bin目录放进环境变量,运行allure --version看看是否安装成功
htmlhttps://repo.maven.apache.org/maven2/io/qameta/allure/allure-commandline/
3.生成报告
yamladdopts = -vs -m "smoke or user" --alluredir=./temp --clean-alluredir#表示将报告生成在temp目录下并且每次运行都先清楚之前的报告
问题:执行用例后allure乱码,将pycharm、allure加入环境变量,pycharm:file-setting-Editor-File encoding-GBK
cookie、session、token相同点不同点
cookie储存在客户端,session存在服务器,session安全性比cookie高,所有重要的东西放在session,不重要的放在cookie
session存在服务器内存,token存在硬盘文件里或者数据库中,token比session更省资源,token鉴权只需要在服务器端解密即可
测试内卷:劳动力,功能测试岗位
技术:内卷不严重
pytest执行流程:
1.查询当前项目下的文件conftest.py并执行
2.查询pytest.ini文件,寻找testcae位置
3.查询用例目录下conftest.py文件并执行
4.查询py文件中是否有setUp tearDown setup_class tearDown_class
5.根据pytest.ini文件中的测试用例规则去查找用例并执行
pytest断言
pythonassert flag is True
assert 1==1
assert 'a' in 'abc'
自动化实施过程:
1.可行性分析
2.框架选择
3.需求分析
4.制定计划
5.测试用例设计
6.环境搭建
7.版本控制,持续集成,生成报告
8.脚本维护
主流应用微服务架构
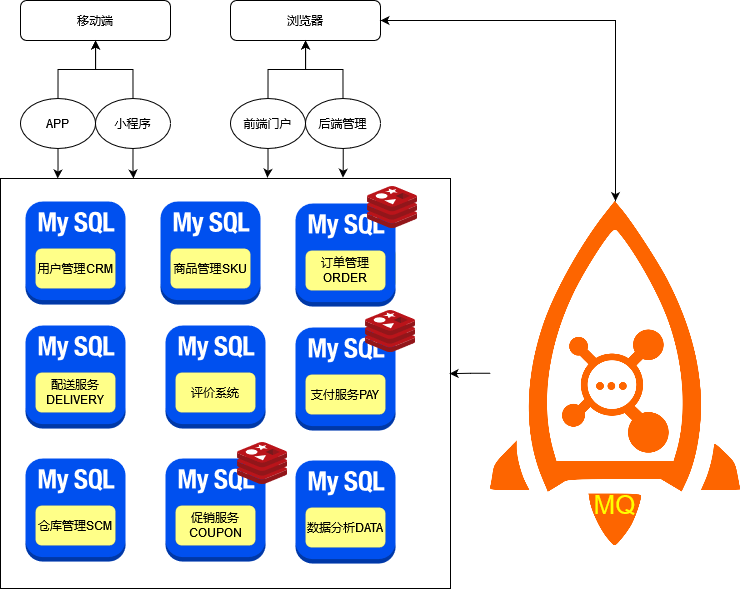
MQ(Message queue)消息队列
是一种基础的数据结构,先进先出的特点,主要为了实现高性能,高并发的中间件
RabbitMQ、ActiveMQ、RocketMQ、Kafka
主要的作用:异步、解耦、削峰(消除流量高峰)
Redis:
安装:windows下载解压打开即用,redis属于nosql,通过命令操作增删改查
命令不区分大小写,命令可以通过tab补全
redis有五种数据类型:string字符串、List列表、Set集合、Hash哈希、Ordered Set有序列表
String存储的是二进制的key=value
1.设置一个字符串以及获取一个字符串
powershell127.0.0.1:6379> set job takeDownCCP 127.0.0.1:6379> get job
2.批量设置多个字符串以及获取
powershell127.0.0.1:6379> mset who NFSC time 2025 127.0.0.1:6379> mget who time
3.查看所有Key
powershellkeys *
4.查看key是否存在
powershell127.0.0.1:6379> exists who
5.给指定的key和value追加值
powershell127.0.0.1:6379> append who er
6.查看一个key的长度
powershell127.0.0.1:6379> strlen who
7清空数据库
powershell127.0.0.1:6379> flushdb
pythonimport redis
#创建一个数据库连接池
pool = redis.connectionPool(host="localhost", port='6379')
#从连接池获取一个连接
conn = redis.Redis(connection_pool=pool)
#设置一个字符串以及获取
conn.set("job", "takeDownCCP")
print(conn.get("job"))
#批量插入和批量获取
conn.mset({"who": "NFSC", "time": "2025"})
print(conn.mget("who", "time"))
#查看redis库中有哪些key
print(conn.keys())
#判断一个key是否存在
print(conn.exist("job"))
#追加值
conn.append("who", "er")
print(conn.get("who"))
#查看string的长度
print(conn.strlen("job"))
#清空redis
conn.flushdb()
print(conn.keys())
2022-11-01
UI自动化框架选择
如果有前端基础:cypress
如果只测试web项目使用,不打算测试App:playwright
其他的无脑选Selenium
环境搭建:python+浏览器+Selenium+浏览器驱动
发现:python package中都含有空文件,即该文件夹可被引用
问题:webdriver版本过高,不匹配本机chrome版本,查看
webdriver版本方法:在其目录下打开
powershellcmd:chromeDriver -v
升级chrome浏览器即可
浏览器的交互:
selenium以面向对象的思路完成自动化
获取数据:就是访问对象的属性
操作数据:就是调用对象的方法
所以对浏览器的控制就是对driver对象的方法进行调用
常用的driver对象方法和属性
pythonmaximize_windows()#最大化窗口
get(url)#跳转至指定页面
refresh()#刷新
back()#后退
forward()#前进
get_screenshot_as_png()#截图的base64内容
get_screenshot_as_file(path)#截图保存到文件
current_url#当前网址
page_Source#网页源码
current_windows_handle#当前窗口
windows_handles#所有窗口
switch_to.alert#处理网页弹窗
switch_to.frame('frame_name')#切换框架
switch_to.windows('windows_name')#切换窗口
| 定位器 | 描述 |
|---|---|
| id | 定位id属性与搜索值匹配的元素 |
| name | 定位name属性与搜索值匹配的元素 |
| tag name | 定位标签名称与搜索值匹配的元素 |
| class name | 定位class属性与搜索值匹配的元素(不允许使用复合类名) |
| #以上四个为根据属性来定位 | |
| link text | 定位link text可视文本与搜索值完全匹配的锚元素#精确文字匹配 |
| partial link text | 定位link text可视文本部分与搜索值部分匹配的锚点元素#模糊文字匹配 |
| #通过文本定位 | |
| xpath | 定位与Xpath表达式匹配的元素 |
| css selector | 定位css选择器匹配的元素 |
| #通过底层部分定位 |
html<input #标签名
id="kw" #该标签的id属性,一个页面中有唯一性的约束,其他属性都可重复
name="wd"
class="s_ipt"
value=""
maxlength="255"
autocomplete="off">
pythondriver.find_element(By.TAG_NAME, "input")
driver.find_element(By.ID, "kw")
driver.find_element(By.name, "wd")
driver.find_element(By.CLASS_NAME, "s_ipt")
driver.find_elements(By.TAG_NAME, "input")[7]
#返回一个list取下标索引定位
driver.find_elements(By.LINK_TEXT, "新闻")#精确文字匹配
driver.find_elements(By.PARTIAL_LINK_TEXT, "新")#模糊文字匹配
以上为百度输入框的html属性:
html<input #标签名
class="gLFyf gsfi" #class类名
jsaction="paste:puy29d;"
maxlength="2048" name="q" #该标签的name
type="text"
aria-autocomplete="both" aria-haspopup="false" autocapitalize="none" autocomplete="off"
autocorrect="off" autofocus="" role="combobox" spellcheck="false" title="Search" value="" aria-label="Search" data-ved="0ahUKEwi_s4_q2Yz7AhVRm1YBHWLiBb8Q39UDCAQ">
以上为google输入框的html属性
pythondriver.find_element(By.TAG_NAME, "input").send_keys("selenium")
根据表达式进行定位
CSS和XPATH如何选择(css性能高一些,为什么以后再问) 如果有前端开发配合,有前端基础,选择css
如果没有前端配合,选择xpath
XPATH语法
-
支持层级跳转
- /根路径
- //任意层级
- *任意元素
- @属性筛选
- 位于中间的/表示下一级
- .本机
- ..上一级
- 支持布尔值
- 支持函数
-
支持布尔值
-
支持函数
-
text获取元素内的文本 #精确匹配
-
contains任意位置包含 #模糊匹配
-
starts-with以什么开头。#半模糊匹配
-
XPATH调试
手写Xpath出来后,F12调试再写入代码
js$x('//input')
pythondriver.find_elements(By.XPATH, "/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input")
元素的属性:
| 属性 | 内容 | 例子 |
|---|---|---|
| id | 唯一标记 | kw |
| tag_name | 标签名 | input |
| location | 元素坐标 | {'x':300, 'y':400} |
| size | 元素大小 | {'height':300, 'width':400} |
| rect | 元素范围 | {'height':300, 'width':400, 'x':300, 'y':400 } |
| parent | webdriver实例 | |
| screenshot_as_base64() | 截图base64内容 | base64编码 |
| screenshot_as_png() | 截图的二进制内容 | 略 |
| get_attribute(name) | 获取元素的html属性 | |
| value_of_css_property | 获取css属性 | |
| click() | 点击 | |
| clear() | 清空内容 | |
| send_keys(content) | 输入内容 |
强制等待:
pythontime.sleep(10)
隐式等待:
pythondriver.implicitly_wait(10)#大于0的参数,表示启用隐式等待,不能判断元素是否出现
显式等待:
pythonelem = webDriverWait(driver, 10).until(
lambda _: driver.find_element(
By.XPATH, "/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input"
)
)
POM
1.写出元素定位的表达式
2.写出合适的等待方式
3.维护各个元素的定位表达
page object model 页面对象模型
- 类 表示页面
- 类属性 表示页面的元素
- 类方法 表示对页面的操作
2022-11-02
基于pytest搭建UI自动化框架
-core
|-pom.py #封装的各种PO
-testcase #测试用例
|-test_order.py
|-test_pay.py
-main.py #框架启动入口
重构线性代码用例
- 打开百度、谷歌
- 输入selenium回车
- 截图并返回上一页
- 断言网页标题是否为百度、谷歌
2022-11-03
使用fixture将开启关闭浏览器操作封装
python# fixture固件
import pytest
from selenium import webdriver
from common.yamlUtil import clearYaml
@pytest.fixture(scope="function", autouse=False)
def connMysql():
print("开始ui自动化")
clearYaml()
yield
print("结束ui自动化")
@pytest.fixture(scope="session", autouse=True)
def driver():
driver = webdriver.Chrome()
yield driver
driver.quit()
日志和截图
-
创建配置文件
-
创建logger
-
创建钩子hook
-
钩子是框架在运行过程中自动执行的代码
-
夹具是用例运行中执行的代码
-
conftest.py
python# fixture固件
import logging
import time
import pytest
from selenium import webdriver
from common.yamlUtil import clearYaml
logger = logging.getLogger(__name__)
@pytest.fixture(scope="function", autouse=False)
def connMysql():
print("开始ui自动化")
clearYaml()
yield
print("结束ui自动化")
@pytest.fixture(scope="session", autouse=True)
def driver():
driver = webdriver.Chrome()
yield driver
driver.quit()
def pytest_runtest_setup(item):
logger.info(f"开始执行:{item.nodeid}".center(60, "-"))
def pytest_runtest_teardown(item):
logger.info(f"结束执行:{item.nodeid}".center(60, "-"))
@pytest.hookimpl(hookwrapper=True)
def pytest_runtest_makereport(item, call):
outcome = yield
report = outcome.get_result()
path = f'images/{time.time()}.png'
if report.when =='call':
o = report.outcome
s = f"用例执行结果: 【{report.outcome}】"
if o =='failed':
logger.error(s)
elif o == 'skip':
logger.warning(s)
else:
logger.info(s)
if "driver" in item.fixturenames:
driver = item.funcargs["driver"]
logger.info(f"界面截图:{path}")
driver.get_screenshot_as_file(path)
2022-11-04
DDT+csv
python# -*- coding: utf-8 -*-
# @Time : 2022/11/3 16:26
# @Author : ciskp
# @Email : noEmail@qq.com
# @Describe : 为框架加载数据
import csv
from pathlib import Path
data_dir = Path(__file__).parent.parent / 'data'
# 标识ddt_test_inputStr路径
#__file__表示当前路径下的东西
def read_csv(filename):
path = data_dir / filename
print(path)
with open(path, encoding='gbk') as f:
reader = csv.DictReader(f)
for i in reader:
yield list(i.values()) # 此处是一个生成器
if __name__ == '__main__':
for j in read_csv("ddt_test_inputStr.csv"):
print(j)
上传文件:
python# @pytest.mark.UI
def test_uploadFile(self, driver):
driver.get( 'file:///C:/Users/ciskp/Desktop/%E6%96%B0%E5%BB%BA%E6%96%87%E6%9C%AC%E6%96%87%E6%A1%A3.html')
elem = driver.find_element(By.XPATH, '/html/body/input')
elem.send_keys(r'E:\pythonProject\百度一下回车后截图.png')
#r=row原始内容,不打算转义
driver.get_screenshot_as_file('1111.png')
为什么上传文件不能用相对路径
因为selenium执行路径是:python→webdriver→chrome
每一个节点的看到的相对路径不一致有歧义,导致不能准确找到文件
定位不到元素不要直接sleep,导入debugger包定位为什么
webdriver-helper
2022-11-07
#python保留的关键字
pythonimport keyword
print(keyword.kwlist)
>>>['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
#python保留的关键字
python六个基本数据类型
3个不可变数据(可哈希):Number数字、String字符串、Tuple元组
3个可变数据:List列表、Dict字典、Set集合
可迭代对象为:String字符串、Tuple元组、List列表、Dict字典、Set集合
python3.10中所有内置数据类型
| 文本类型 | str字符串 |
|---|---|
| 数字类型 | int, 整型 float, 浮点数 complex复数 |
| 序列类型 | list, 列表对应java数组 tuple, 元组 range创建的整数范围 |
| 映射类型 | dict字典对应java的map对象 |
| 集合类型 | set, 可变集合 frozenset不可变集合 |
| 布尔类型 | bool布尔值(True或False在内存里对应1或0) |
| 二进制类型 | bytes,二进制形式 bytearray, memoryview |
字符串方法
字符串是数组, 支持索引
Python 中的字符串是表示 unicode 字符的字节数组。
支持索引,从0开始,字符串索引不会引发索引越界
pythona = 'Hello, world'
print(a[0]) #按照索引返回具体值
a.find('H')#返回找到H的最低索引
裁切[1:7]返回位置1到位置7(不包括),左闭右开
pythonb = 'Writing python'
print(b[1:7])
负索引
字符串索引不会引发索引越界
pythonb = 'Writing python'
print(b[-1:-7])# 负数索引也是从左往右
字符串长度
pythonb = 'running python'
print(len(b))
字符串常用方法
strip()删除开头或结尾的字符,不传参默认删除空白,也可删除指定字符
pythona = ' Hello World '
a.strip()#'Hello World'
a.lstrip()#'Hello World '
a.rstrip()#' Hello World'
b = 'Hello World'
b.strip('d')#'Hello Wrol'
b.lstrip('H')#'ello Wrold'
a.find('e')# 返回找到e的第一个索引,没找到返回-1
str.find(str, beg=0, end=len(string))
Decode it.
## 二进制转换字符串
>>> b'a string'.decode('ascii')
'a string'
To get bytes from string, encode it.
# 字符串转换二进制
>>> 'a string'.encode('ascii')
b'a string'
# 二进制转换十进制
print(int('101', 2))
5
#将二进制的101转成十进制的5
如果想去除中间的空格使用replace(), a.reverse()#反转字符串
pythona = 'Hello World'
a.replace(' ', '')#'HelloWorld'
a.reverse()#反转字符串
从文件中读取多行数据并打印
pythonwith open(filename) as f:
lines = (line.strip() for line in f)
for line in lines:
print(line)
split()按照指定分隔符拆分字符串为子字符串的列表
pythona = 'Hello,World'
print(a.split(','))# ['Hello', 'World'],a.split()不传参用任意长度空格分隔
in 或 not in 关键字,检查指定字符串是否在字符中
pythona = 'request python'
m = 'qu' in a
n = 'rs' not in a
print(m)
print(n)
+组合两个字符串
str+= "happy"表示向str字符串后面追加"happy"
str.count()返回子字符串重复的次数
str.endswith(), str.startswith()判断结尾(开头)的字符是否相符
str.find()字符串中查找子字符串,相似方法str.rfind(), str.index(), str.rindex()
pythonstr.is***()判断字符串是否满足条件
isalnum()#如果字符串中的所有字符都是字母数字,则返回 True。
isalpha()#如果字符串中的所有字符都在字母表中,则返回 True。
isdecimal()
isdigit()
isidentifier()
islower()
isnumeric()
isprintable()#如果字符串中的所有字符都是可打印的,则返回 True。
isspace()
istitle()#
isupper()#如果字符串中的所有字符都是大写,则返回 True。
正则匹配 所有小写英文字母[a-z] 所有大写英文字母[A-Z] 所有中文汉字和中文标点[!^1-^127] 所有中文汉字(CJK统一字符)[一-龥] or [一-﨩]搜索 所有中文标点[!一-龥^1-^127] 所有非数字字符[!0-9]
str.join(iterable)
将序列中所有的值拼接成一个长字符串
iterable中仅支持字符串
pythonala = ['apple', 'pen']
''.join(ala)#'applepen'
2022-11-08
fnmatch
该模块配合通配符匹配字符串
str.find(), str.endswith(), str,startswith()<fnmatchcase()<re
函数匹配能力介于简单的字符串方法和强大的正则表达式之间
pythonfrom fnmatch import fnmatchcase
[addr for addr in addresses if fnmatchcase(addr, '* ST')]
#['5412 N CLARK ST', '1060 W ADDISON ST', '2122 N CLARK ST']
[addr for addr in addresses if fnmatchcase(addr, '54[0-9][0-9] *CLARK*')]
#['5412 N CLARK ST']
re字符串匹配和搜索
pythonimport re
# Simple matching: \d+ means match one or more digits
if re.match(r'\d+/\d+/\d+', text1):
需要重复使用正则表达式需要先编译,让其缓存起来
pythondatepat = re.compile(r'(\d+)/(\d+)/(\d+)$')
datepat.match('11/27/2012abcdef')
datepat.match('11/27/2012')
最短匹配模式(.*?)匹配任意字符0-N次
这样就使得匹配变成非贪婪模式
pythonimport requests
import re
def restr():
url = 'https://reqres.in/api/users'
res = requests.get(url).text
restr = re.search('"email":"(.*?)@reqres.in"', res).group(1)
print(restr)
restr()
int数字运算符
+-*/ x+=5等价x=x+5 x^3=3等价x=x^3 =赋值运算符
//地板除(结果丢弃小数取整)
==等于运算符
python序列(数组)
python元组tuple
是一种有序且不可更改的集合。允许重复的成员。
f{$function表达式}, r raw, b binary
python(a, b, c) a,b,c tuple()
生成元组的关键是逗号, 而不是小括号()
pythontuple2 = (30,)
# 逗号至关重要
>>> 3 * (40 + 2)
126
>>> 3 * (40 + 2,)
(42, 42, 42)
| count() | 返回元组中指定值出现的次数。 |
|---|---|
| index() | 在元组中搜索指定的值并返回它被找到的位置。 |
元组支持索引,它通常用于函数的返回值
列表比元组灵活,为什么还要用元组来存储数据?
元组和列表最大的区别就是,列表中的元素可以进行任意修改,列表就好比是用铅笔在纸上写的字,写错了可以擦除重写;而元组就好比是用中性笔在纸上写的字,写了就擦不掉了,写错了就得换一张纸。
元组的不可替代性体现在以下这些场景中:
- 元组作为很多内置函数的返回值存在。
- 元组比列表的访问和处理速度要快。因此,当元素明确且不涉及修改时,建议使用元组。
- 元组可以当做映射中的“键”使用,而列表不行。
2022-11-09
python列表list
是一种有序和可更改的集合。允许重复的成员。
pythona = []
list(iterable)
[x for x in iterable] #这三种方法创建列表
print([i for i in range(10) if i%2 == 0])
print([i if i == 0 else 100 for i in range(10)])# 列表生成式
return max(nums) * max(a * b for a, b in [heapq.nsmallest(2, nums), heapq.nlargest(3, nums)[1:]])
# 列表生成式一行写法
sorted(可迭代对象)生成排序好的新列表
支持索引,正负索引取值范围都是左闭右开
pythona = [100, 200, 300]
a.count(100)#对100的元素计数并返回个数
print(a[0])#索引查询列表中的值
for b in a:#for循环查询列表中的值
print(b)
a[0] = 999#修改改列表中的值
print(a)
print(a[0:2:])#列表切片以查询
a[0:1] = [999]#列表切片以修改
print(a)
a[0:0] = [777, 888]#列表空切片以新增
print(a)
a[0:0] = []#列表空切片添加空列表表示删除
print(a)
print(len(a))#返回列表长度
a.append(666)#追加列表成员放置到末尾,所有它的索引为-1
a.insert(-1, 555)#在指定的索引处添加成员
a.remove(555)#按照成员的值删除指定成员
a.pop()#方法删除指定的索引(如果未指定索引,则删除最后一项
del a[0]#删除列表中的值
del a #删除列表
print(a)
a.clear()#清空列表中的值
b = a.copy()#复制列表
c = list(a)#复制列表
a + b + c = d#合并列表
print(d)
for x in b:#将b追加到a中
a.append(x)
print(a)
a.extend(b)#将b追加到a中extend可追加整个列表到a中,但是append只能单个元素追加
a.count()#返回a中指定值的成员个数
a.reverse()#反转列表顺序在源列表基础上原地修改,reversed(a)将结果转换为Python 迭代器,a[::-1]切片反转
a.sort()#对列表排序
min() max()返回序列中最大最小值
查找最大或最小的N个元素
pythonimport heapq
integer = [1, 8, 9, 25, -9, 0, 85, 7]
print(heapq.nlargest(3, integer))#返回3个最大的值
print(heapq.nsmallest(3, integer))#返回3个最小值
nlargest(), nsmallest()都能接收关键字参数
pythonkv = [
{'name': 'IBM', 'shares': 100, 'price': 91.1},
{'name': 'AAPL', 'shares': 50, 'price': 543.22},
{'name': 'FB', 'shares': 200, 'price': 21.09},
{'name': 'HPQ', 'shares': 35, 'price': 31.75},
{'name': 'YHOO', 'shares': 45, 'price': 16.35},
{'name': 'ACME', 'shares': 75, 'price': 115.65}
]
cheap = heapq.nsmallest(3, kv, key=lambda s: s['price'])
expensive = heapq.nlargest(3, kv, key=lambda s: s['price'])
nlargest()nsmallest()时间复杂度O(log N),N是列表长度,因此数据量远大于最值,用heapq
如果只取最大值最小值,用min()max()
如果要取的最值个数接近集合大小时,先排序再切片sorted(item)[
]sorted(item)[-N]
10亿数中10000个数
可以手写一个堆排序取10亿数中最大的10000个数吗?
由于题目给出的数据范围较大,分段读取数据并拆分成小的数据集进行堆排序。
在堆排序的过程中,使用一个大小为10000的小根堆来保存当前可选数据集中最大的10000个数,同时对于每个新的数据集,先将其中的前10000个元素放入堆中,然后依次将剩余的元素与堆中的最小值比较,如果大于最小值,则将最小值替换为当前元素,然后重新对堆进行调整。
最终得到的小根堆中即为最大的10000个数。
代码如下:
pythonimport heapq
def heap_sort(file_path, chunk_size, top_k):
with open(file_path, 'r') as f:
chunk = []
for line in f:
if len(chunk) >= chunk_size:
heapq.heapify(chunk)
while len(heap) > top_k:
heapq.heappop(heap)
chunk = []
chunk.append(int(line))
if len(chunk) > 0:
heapq.heapify(chunk)
while len(heap) > top_k:
heapq.heappop(heap)
return heapq.nsmallest(top_k, heap)
if __name__ == '__main__':
file_path = 'test.txt' # 待排序的数据文件
chunk_size = 10000 # 每次读取的数据块大小
top_k = 100 # 需要找出最大的100个数
top_values = heap_sort(file_path, chunk_size, top_k)
print(top_values)
#其中,test.txt为含有10亿个整数的数据文件,我们每次分块处理10000条数据,找出其中最大的100个数,最终输出结果即为最大的100个数。
python集合set
是一个无序和无索引的集合。没有重复的成员。在 Python 中,集合用花括号{}编写。
set可以被用作字典的键
pythona = {'g', 'y', 'r', 'c', 'g', 'y'}
a = set()
#注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
print(a)#{'g', 'r', 'c', 'y'}#集合可以去掉重复元素
for x in a:#for循环查询集合中的值
print(x)
print('g' in a)#'g'是否存在a中
a.add('a')#添加一个成员
a.update(${iterable})#添加多个成员
a.remove('g')#删除指定成员,值不存在报错
a.discard('g')#删除指定成员,值不存在不报错
a.pop()#方法删除最后一项
a.clear()#清空集合
del a #删除集合
b = {1, 2, 3}
c = a.union(b)#合并a和b
c = a.intersection(b)#返回a和b的交集于c
c = a.isdisjoint(b)#返回a和b是否有交集
python字典Dictionary
是一个无序,可变和有索引的集合。没有重复的成员。
| 方法 | 描述 |
|---|---|
| get() | 返回指定键的值 |
| keys() | 返回包含字典键的列表 |
| values() | 返回字典中所有值的列表 |
| items() | 返回包含每个键值对的元组的列表 |
| pop() | 删除拥有指定键的元素 |
| popitem() | 删除最后插入的键值对 |
| setdefault() | 返回指定键的值。如果该键不存在,则插入具有指定值的键。 |
| update() | 使用指定的键值对字典进行更新 |
pythonbook = {
"appId": "wxa033f083bd79132d",
"timestamp": 1667983270,
"nonceStr": "4GehgOJ1Kj",
"signature": "74fc952723c1d4554ed0df36ee9d9e7c1577bd77",
"jsApiList": [
"updateAppMessageShareData", "updateTimelineShareData"
]
}
val = book.get('appId')#获取 "appId" 键的值
book["appId"] = 'qea033f083bd79132d'#通过键修改值
for i in book:#遍历book的所有键名
print(i)
for i in book:
print(book[i])#遍历book的所有值
for i in book.values():#遍历book的所有值
print(book[i])
for i,j in book.items():#遍历book的所有键值
print(i,j)
print(len(book))
book.pop("appId")#通过键删除值
print(list(book))#返回字典中所有键的列表
print('appId' in book)#查找键appId是否存在book中
字典排序
一个字典需要迭代或序列化的时候保持元素的顺序
pythonfrom collections import OrderedDict
OrderedDict 内部维护着一个根据键插入顺序排序的双向链表。
每次当一个新的元素插入进来的时候, 它会被放到链表的尾部。
对于一个已经存在的键的重复赋值不会改变键的顺序。
但是,一个ordereddict大小是dict的两倍,故需考虑大数据量下内存消耗问题
字典运算
在字典中求最大值、最小值、排序
pythonprices = {
'ACME': 45.23,
'AAPL': 612.78,
'IBM': 205.55,
'HPQ': 37.20,
'FB': 10.75
}
minPrice = min(zip(price.values(), price.keys()))
maxPrice = max(zip(price.values(), price.keys()))
ascPrice = sorted(zip(price.values(), price.keys()))
查找两字典的相同点
pythona = {
'x' : 1,
'y' : 2,
'z' : 3
}
b = {
'w' : 10,
'x' : 11,
'y' : 2
}
a.keys() & b.keys() # { 'x', 'y' }键相同
a.keys() - b.keys() # { 'z' }值相同
a.items() & b.items() # { ('y', 2) }键值都相同
删除序列中相同元素并保持顺序
如果序列(字符串、列表、字典、元组)上的值都是不可变数据类型(数值型、字符串、元组、布尔)即hashable类型
python'''
先创建一个集合,循环形参成员,判断成员是否存在于集合
是就退出判断,否就新增进集合
'''
a = [1, 3, 7, 5, 7, 3, 9, 1, 4, 7, 66, 66]
def dedupe(items):
distinct = set()
for item in items:
if item not in distinct:
yield item
distinct.add(item)
print(list(dedupe(a)))
with open(somefile,'r') as f:#读取文件消除重复行
for line in dedupe(f)
python基本语句
if:
elif:
else:
finally:
pythontry:
1 0
except ZeroDivisionError:
print("Can't divide anything by zero.")
finally:
print("Done trying to calculate 1 0")
pythonwith open("somefile.txt") as myfile:
dosomething(myfile)
# 到这里时文件已关闭
类定义
pythonclass Doubler:
def __init__ (self, value):#初始化对象属性
self.value = value
def double(self):
self.value *= 2
pythonlambda parameters: expression#类似于下方
def <lambda>(parameters):
return expression
generator生成器
在python中有一种一边循环一边计算的函数成为generator生成器
yield 表达式只能在函数定义的内部使用 yield 表达式。
JSON
javascript object notation
json.loads(x)#将str转换为dict
json.dumps(x)#将dict转换为str
pythonimport json
x = '{"name":"wang", "age":69, "city":"Beijing"}'
y = x.json.loads(x)#将str转换为dict
x = {"name":"wang", "age":69, "city":"Beijing"}
y = x.json.dumps(x)#将dict转换为str
可以把以下类型的 Python 对象转换为 JSON 字符串:
| Python | JSON |
|---|---|
| dict | Object |
| list | Array |
| tuple | Array |
| str | String |
| int | Number |
| float | Number |
| True | true |
| False | false |
| None | null |
时间import datetime
pythonimport datetime
x = datetime.datetime.now()
print(x.strftime("%Y-%m-%d %H:%M:%S:%f"))
2022-11-10
try异常
pythontry:
...
except NameError as e:
..
except:
...
else:
...
finally:
...
#python遇到未被处理或捕获的异常会终止程序并显示错误信息(traceback)
类/对象
函数
python# 接受数量不定的位置或关键字参数
def spam(*args, **kwargs):
# args 是一个位置参数的元组
# kwargs 是一个关键字参数的字典
...
pythondef callfunc(*args, **kwargs):
func(*args,**kwargs)
*arg和**kwargs通常用来为其他函数编写包装器,上述callfunc()接受任意的参数组合,将他们传递给func()函数
装饰器
大多用于一下场景:插入日志、性能测试、事务处理、缓存、权限校验
标准库
comb(n, k) 和 perm(n, k=None) 函数。
两者都用于计算从 n 个无重复的元素中选择 k 个元素的方法数,
comb返回无序计算的结果,而
perm返回有序计算的结果。(译注:即一个求组合数,一个求排列数)
format(value, format)
pythondef format(__value: object,
__format_spec: str = ...) -> str
# 形参value为对象,format_spec意思是准换成什么格式,出参是str
'b' - 二进制格式
'c' - 将值转换为相应的 unicode 字符
'd' - 十进制格式
'o' - 八进制格式
'x' - 十六进制格式,小写
'X' - 十六进制格式,大写
'n' - 数字格式
x = format(0.5, '%')#将0.5准换成百分数
x = format("11", 'b')#将11字符串转换城二进制
2022-11-11
while循环
pythonwhile True:#条件为真的前提下循环执行下面代码,直到条件为假结束循环
print("hello")
break提前结束(跳出)循环,跳出整个while循环
pythona = 0
while a < 10:
if a >8:
break
print(a)
a += 1
continue结束本次循环,下面的代码不运行了,从头开始
pythona = 0
while a < 10:
a += 1
if a % 2:
continue
print(a)
Pymysql
'cryptography' package is required for sha256_password or caching_sha2_password auth methods
undefinedpip install cryptography#解决方法
''' 引入包,定义连接参数,使用try语句块连接mysql ''' import pymysql try: mysql = pymysql.Connection(host="127.0.0.1", user="root", password="123456", database="sys", port=3306) exec = mysql.cursor() exec.execute("SELECT * FROM `sys`.`dir_articles` limit 1;") result = exec.fetchall() for item in result: print(item) except Exception as error: print(error) finally: mysql.close()
忘记mysql密码
关闭mysql服务win+r 关闭服务
填写启动参数:
powershell--skip-grant-tables
启动mysql
登录mysql服务,navicat修改root账户密码
修改navicat连接密码
停止mysql去掉启动参数再次启动
2022-11-12
Appium自动化
环境安装
- 安装JDK
- 安装AndroidSDK
- 安装Appium server
- 安装模拟器或真机
- 安装appium-python-client
APP自动化原理
自动化脚本→Appium Server→AndroidSDK→手机终端
Desired Capbilities-Appium自动化配置
pythondesired_caps = {
"platformName":"Android",
"platformVersion":"5.1.1",
"deviceName":"xiaomi",
"appPackage":"com.taobao.ali",
"appActivity":"com.xxx.xxx.xx.xx",
"noReset":"True"
}
ADB命令
pythonadb connect IP:PORT#连接模拟器
adb devices#查看设备
aapt dump badging $apk路径#查看被测app的报名和启动页面
Appium定位工具UIautomatorviewer(安卓sdk自带)
POM设计原理
python一个对象=属性+行为
第一层:base层,描述每个页面相同的属性及行为
第二层:pageobject层,每个页面独有的特性及独有的行为
第三层:testcases层,用例层。描述项目业务流程
第四层:testdata数据层
2023-2-2
python面试题
深浅拷贝:
pythonimport copy
old = [[1,2],[3,4]]
new = copy.copy()
# 浅拷贝新开辟一块内存地址复制源对象的容器,但是源对象的指针指向两个容器,故源对象修改后,拷贝对象也被同步修改,源容器新增对象,新容器不会新增,因为源容器的新对象指针不会被复制指向新容器
print()
new = copy.deepcopy()
# 深拷贝新开辟一块内存地址复制源对象容器,然后递归将元素复制到新容器中,两容器id不同其元素指针指向各自容器
各数据结构特点,区别
数组Array:一种线性表数据结构,用一组连续的内存空间来存储一组相同类型的数据
链表Linklist:其内存地址不连续,无顺序,由一系列节点组成,每个节点由数据data和指向下一个节点的指针pointer组成
栈stack:线性结构,后进先出
队列queue:线性结构,先进先出,操作数据是从两端进行,队列头删除,队列尾添加一些消息中间件采用队列模型以解耦业务
哈希表hashtable:存储着由键值对组成的数据,通过键直接访问存储数据,查找过程:输入key,由哈希函数计算成数组下标,通过下标查询具体值,时间复杂度O(1)
树tree:树是一种层级式数据结构,由顶点和边组成,常见二叉树(树的度为2,每个节点至多有两个子树)
堆heap:堆是一个完全二叉树(除了最后一层其他层节点个数都是满的),父节点<=子节点叫Minheap,父节点>=子节点叫maxheap
图graph:由顶点和连接每对顶点的边构成的图形就是图,图按照顶点指向方向分为有向图,无向图,常见图遍历算法就是广度优先算法和深度优先算法
2023-2-3
垃圾回收机制
python内存管理机制=垃圾回收机制+内存池机制
垃圾回收:以引用计数法为主,标记清除为辅
引用计数法:指每个对象的结构体PyObject中定义一个计数变量ob_refcnt, 计算该对象被引用的次数,
有4种增加计数的场景:
- 该对象被引用
- 该对象被加入某容器(列表、元组、集合、字典)
- 对象被创建
- 该对象被作为参数传到函数中
有4种减少计数的场景:
- 该引用被释放,也就是说引用该对象的变量换了引用对象
- 该对象被从容器中删除
- 使用del方法删除了该对象
- 该对象离开作用域,例如函数全部执行完毕
当计数变量ob_refcnt==0时,自动释放该变量,故没有内存泄漏风险
优点:高效,自动释放,实时性高。
缺点:1增加储存空间,维护引用计数消耗资源,2无法解决循环调用(一组未被外部引用,但相互指向的对象)
标记清除法: 作为解决容器中循环引用的情况,辅助python进行垃圾回收
- 标记阶段:遍历所有对象,如果是可达的(reachable)就是还有指针引用它,那么标记为该对象可达reachable
- 清除阶段:再次遍历对象,如果某个对象没有被标记为可达reachable,则将其回收。
新的对象被创建后,gc会记录被分配的对象数量与释放对象的数量,当两者之差超过threshold0(700)时,gc扫描启动,检查第0代,没有标记可达的清除,剩下的对象放到第1代,
如果第0代剩下的对象与第1代将被释放的对象之差超过threshold1(10)时, gc启动,检查第1代和第0代,没有标记可达的被清除,剩下的对象放到第2代,
如果第1代剩下的对象与第2代将被释放的对象之差超过threshold2(10)时,gc启动,检查第2代和第1代和第0代,没有标记可达的被清除,剩下的还在第2代。
【可达reachable对象会被放到一个“Object to Scan”链表中, 没有可达标记的对象就被标记为GC_TENTATIVELY_UNREACHABLE,并且被移至”Unreachable”链表中,当“Object to Scan”与”Unreachable”个数之差超过当前世代gc阈值gc.get_threshold()时gc启动,上面垃圾回收gc阶段,会暂停整个应用程序,等待标记清除结束后才恢复程序运行, 在分代行为中存活越久扫描次数越少(大部分都在0代中扫描)进行标记清除,提高效率】
为什么世代越老扫描越少,例如0代新加一个对象就扫描一次,同时2代的可达对象和待清除对象不变所以2代此时不扫描,故世代越老扫描越少。
 遗留问题:object to scan 和 unreachable是容器吗?
遗留问题:object to scan 和 unreachable是容器吗?
总结:通过引用计数进行垃圾回收,
通过标记-清除解决容器内对象循环引用问题,
用分代回收以空间换时间提高垃圾回收效率
内存池机制: PYTHON引用了一个内存池memory pool机制,即pymalloc机制,用于小块内存的申请释放,当创建大量小内存的对象时,频繁调用malloc/new导致大量内存碎片,导致效率降低。内存池预先在内存中申请一定数量,大小相等的内存块留作备用,当有新的内存需求时,先从内存池中分配给该需求,不够再去申请新内存,对象释放后,空闲小内存返回内存池,避免频繁内存释放动作。
优点:能够减少内存碎片,提升效率。

2023-2-6
python缓冲池
python对象三要素:id、type、value
代码块:一个模块、一个函数、一个类、一个文件,但在cmd中每条指令都是一个代码块
如果在同一代码块中,采用同一代码块缓存机制,
同一代码块下int(float)、str、bool的id一致会复用
如果不同代码块,则采用小数据池驻留机制,以下小数据池缓存对象在python启动时创建
- int[-5,256]左闭右闭、
- str(由长度为0和1字符串,ASCII字母、数字、下划线组成的才缓存)、
- bool
字符串缓存池:维护一个字典结构的储蓄池,当编译时,如果字符串已经存在于池子不再创建新的字符串,直接返回创建好的字符串对象,如果不存在,先创建对象再加入池子
优点:id或value相同的字符串,直接从池子拿来用,避免创建销毁,提升效率、节约内存
列表缓冲池:列表缓冲池由数组实现,最多维护80个PyListObject对象,创建PyListObject时,先检测缓存池free_list是否有可用对象,有的话直接用,没有通过malloc在内存上申请。
pythonlist1 = [1,2,3]
print(id(list1)) # 123456789
del list1 # list1删除后被添加到数组尾部
list2 = [1,2,3]
print(id(list2)) # 123456789 # 从数组尾部拿这个对象,所以id一致,避免申请内存,注意这里id是list[]这个容器的id,不是容器内成员id
字典缓冲池: 与列表缓冲池相似,由数组维护最多80个PyDictObject对象。开始时,池子里什么都没有,直到第一个PyDictObject对象被销毁,缓存池才接纳被销毁对象
装饰器原理与实现
装饰器就是装饰器函数,本质是个函数,用来修改原函数的一些功能,使得原函数不需要修改
起到增强作用,我把它叫作增强器,或者外挂🤣
总结:函数中传递函数,被传递的函数返回值在函数中返回
使用场景:代码中插入日志、性能测试、事务处理、缓存、权限校验等
pythondef mydecorator(func):
def wrapper():
print("这里是装饰器")
func()
return wrapper
@mydecorator
def hello():
print("被装饰的函数")
hello()
# "这里是装饰器"
# "被装饰的函数"
# 执行顺序:1.运行@mydecorator语法糖,2运行wrapper() 3运行打印 4运行func()传参是hello这个函数所以打印"被装饰的函数",6返回wrapper结束
进程,线程,协程区别实现
进程:一个运行的程序就是一个进程,进程是计算机能分配的最小单位,拥有自己的独立内存空间,所以进程间数据不共享,开销大
线程:调度执行的最小单位,也叫执行路径,不能独立存在,线程以来进程,多个线程之间共享内存(数据、全局变量共享),换句话说一个程序是货拉拉,需要从A搬家到B,一辆货拉拉需要10次搬完(一个线程跑10次),那么10辆车1次搬完(10个线程跑1次)。提高了效率
协程:又称微线程,coroutine,一种用户(写程序的人)创建分配的轻量级线程。他有自己的寄存器和栈,在协程离开后回来时,可以进入上次逻辑流位置。相当于windows开机后可以把上次关机时的没关闭的浏览器再打开且自动打开没浏览完的网页,恢复上次状态
生成器与迭代器
生成器:本质上是一个函数但它用yield返回,它记住了上一次返回时函数的位置,调用生成器第二次或第n次,会跳转到上一次函数挂起的位置,而且记录了程序执行的上下文。所以它记住了数据状态,还记住了程序位置,适合需要遍历处理海量的数据,大日志文件使用readlines()生成一个生成器
迭代器:是一种有序序列,但不知道长度,只能通过next()计算下一个数据,类似懒加载,如列表中1亿个元素,一次性加载需要很大内存,迭代器只需几十字节,调用next()才加载一个
区别: 生成器是生成元素,迭代器是访问元素的一种方式
简述GIL全局解释器锁
global interpreter lock 每个线程执行过程中都需要先获取GIL锁,保证同一时刻只有一个线程在运行
锁定的是解释器,不是代码,防止多线程同时访问python的对象
2023-2-7
自动化---设计模式
单例模式:是一种创建型软件设计模式,保证一个类只有一个实例,并提供一个访问该实例的全局节点,
场景:
- 数据库连接池,多线程池是一个单例,
- 在工具类utils中定义的大量静态常量和静态方法,是一群单例,
- 需要接口关联的场景实例化session,
- 生成唯一id的场景是一个单例,
- 程序的打日志应用,是一个单例,
工厂模式:一个创建对象的函数可以叫工厂模式,只需传入具体参数就能生成对象,解耦代码
场景:依赖具体环境创建不同实例,这些实例都有相同行为,可用工厂模式。
po模式:多用于UI自动化,page页面,object对象
将网页转化成python对象,对网页的流程操作、元素操作转化成对象的方法,元素的定位转化成对象的属性。
数据驱动模式:
setTimeout(function(){debugger}, 2 * 1000 );
在控制台,输入以上代码,在2秒后,就会冻结窗口,和暂停脚本效果一致。 然后再去查找元素,就可以非常容易的查找到元素了。 具体几秒后冻结窗口,就自己把握了。
算法考核的范围和难度
我这次遇到的题目几乎都是可以在 leetcode 上找到原题的,即便没有原题也是一个原题之上的变种, 所以大家刷题上还是以 leetcode 为主。 难度上只遇见过 2 次中等难度, 其余的都是 easy 程度的题目,最多遇到的是链表和双指针相关的题目。 可以看出来市场对于测试开发人员在算法上的考核要比研发序列轻松。